- Why Use K-Nearest Neighbors (KNN)?
- What is K ?
- Difference Between KNN and Other Algorithms
- Types of Distances in KNN
- Euclidean Distance
- Manhattan Distance
- Minkowski Distance
- Advantages of KNN
- Disadvantages of KNN
- Code Example: KNN Classifier
In the vast landscape of machine learning algorithms, K-Nearest Neighbors (KNN) holds a significant place due to its simplicity and effectiveness. It belongs to the family of supervised learning algorithms and is primarily used for classification and regression tasks. Let’s delve into what KNN is, why it’s used, how it differs from other algorithms, the types of distances it utilizes, its advantages, disadvantages, and finally, we’ll walk through a fully working code example.
Why Use K-Nearest Neighbors (KNN)?
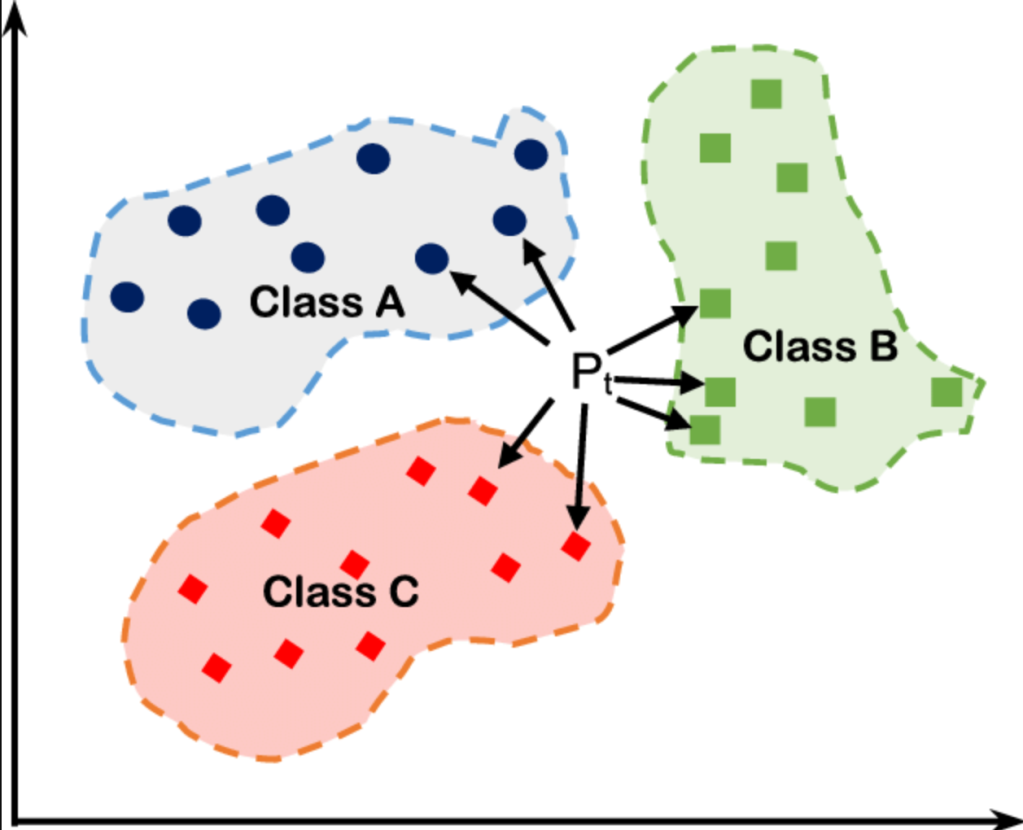
KNN is widely used for its simplicity and intuitive nature. It doesn’t require any training phase, as it stores all the training data points and classifies new data points based on their proximity to existing ones. This makes it particularly useful for small to medium-sized datasets where the decision boundaries are irregular.
What is K ?
K represents the number of nearest neighbors to consider when making predictions for a new data point. It is a hyperparameter that needs to be specified before training the model.
When a new data point is to be classified or predicted, KNN calculates the distances from that point to all other points in the training dataset. It then selects the K nearest neighbors based on these distances. The prediction for the new data point is then determined based on the classes or values of these K neighbors.
The choice of K has a significant impact on the performance of the KNN algorithm. A smaller value of K makes the model more sensitive to noise in the data and can lead to overfitting, where the model captures the noise rather than the underlying pattern in the data. On the other hand, a larger value of K can result in a smoother decision boundary but may also lead to underfitting, where the model fails to capture the complexity of the data.
Difference Between KNN and Other Algorithms
KNN differs from other algorithms in several key ways:
- Instance-based Learning:
KNN is an instance-based learning algorithm, meaning it memorizes the training instances and makes predictions based on their similarity to new instances.
- Lazy Learning:
KNN is often referred to as a “lazy learner” because it doesn’t learn a discriminative function from the training data. Instead, it waits until a query point needs to be classified and then calculates its neighbors.
- Non-parametric:
Unlike algorithms such as linear regression or logistic regression, KNN is non-parametric, meaning it doesn’t make any assumptions about the underlying data distribution.
Types of Distances in KNN
KNN relies on distance metrics to determine the similarity between data points. Common distance metrics include:
- Euclidean Distance
- Manhattan Distance
- Minkowski Distance
- Euclidean Distance: The straight-line distance between two points in Euclidean space. It’s the most commonly used distance metric in KNN.
Euclidean Distance: √(Σ(Xi – Yi)2) from i=1 to n
- Manhattan Distance: Also known as City Block distance, it measures the distance between two points by summing the absolute differences of their coordinates.
Manhattan Distance = Σ(|qi – pi|) from i=1 to n
- Minkowski Distance: A generalized form of both Euclidean and Manhattan distances, where the distance between two points is calculated as the nth root of the sum of the absolute differences raised to the power of n.
Minkowski Distance = (Σ(|qi – pi|r))1/r from i=1 to n
When r = 2, Minkowski distance becomes Euclidean distance, and when r = 1, it becomes Manhattan distance.
Advantages of KNN
- Easy to understand and implement.
- Suitable for Low to Medium range datasets.
- No training phase, making it suitable for dynamic environments.
- Handles multi-class cases effortlessly.
- Can adapt to changes in data distribution over time.
Disadvantages of KNN
- Computationally expensive, especially with large datasets.
- Sensitive to irrelevant features and noisy data.
- Needs careful selection of the distance metric and the value of K.
- Storage of all training instances can consume a significant amount of memory.
Code Example: KNN Classifier
Let’s illustrate how KNN works with a simple Python code example using the scikit-learn library:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Example dataset
data = {
'Feature1': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'Feature2': [2, 3, 4, 5, 6, 7, 8, 9, 10, 11],
'Target': ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B']
}
df = pd.DataFrame(data)
# Displaying column names
print("Column Names:", df.columns.tolist())
# Splitting the dataset into features and target
X = df[['Feature1', 'Feature2']]
y = df['Target']
# Splitting the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initializing the KNN classifier
knn = KNeighborsClassifier(n_neighbors=3)
# Training the classifier
knn.fit(X_train, y_train)
# Making predictions
y_pred = knn.predict(X_test)
# Calculating accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)In this example, we create a synthetic dataset with two features and a target variable. We then split the data into training and testing sets, initialize a KNN classifier with n_neighbors set to 3, train the classifier, make predictions on the test set, and finally calculate the accuracy of the model.
Understanding KNN and its applications is essential for any machine learning enthusiast. While it has its limitations, its simplicity and effectiveness make it a valuable tool in the data scientist’s arsenal. Experimenting with different distance metrics and values of K can lead to improved performance in various scenarios

Leave a comment