Category: Machine Learning
-
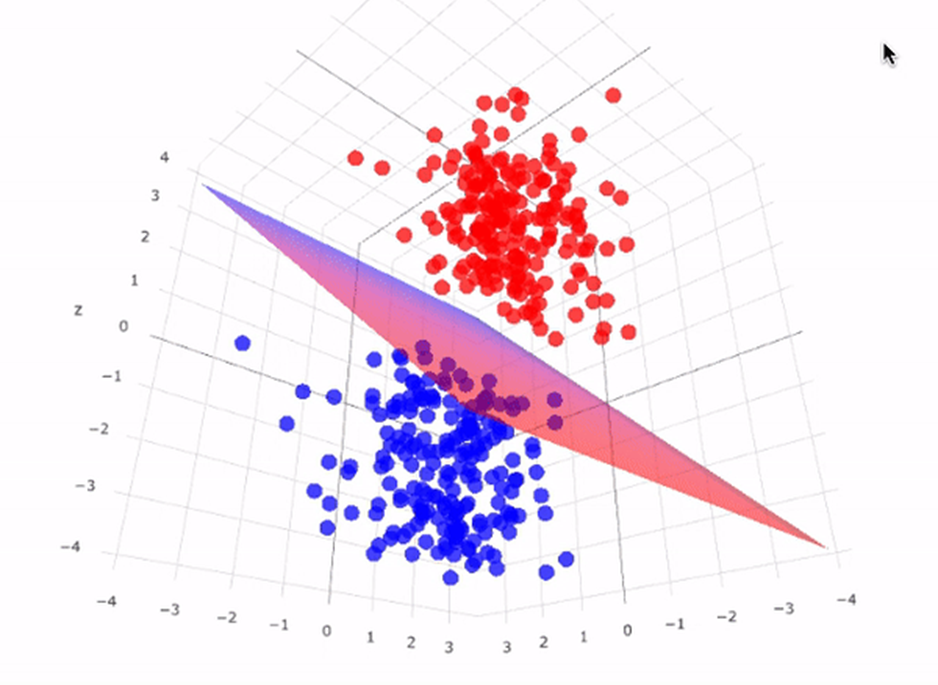
Support Vector Machine(SVM) with Python
Explore the power of Support Vector Machines (SVM) in classification tasks with our latest blog post. Dive into the step-by-step Python implementation of SVM, from data preprocessing to model evaluation. Discover how SVM handles high dimensional data and learn about its versatility through different kernel functions. Visualize the results for…
-
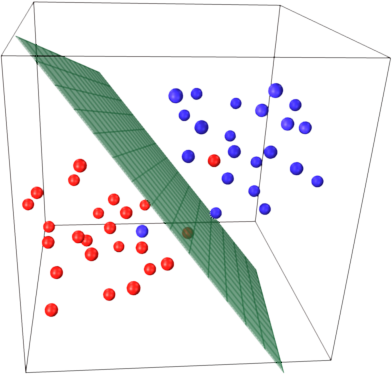
Understanding Support Vector Machines (SVM):
Support Vector Machines (SVM) are foundational in machine learning, excelling in classification and regression tasks. SVMs find optimal hyperplanes to separate classes, utilizing support vectors and the kernel trick for complex data analysis. Widely applied in text classification, image recognition, and bioinformatics, SVMs are pivotal in modern AI and remain…
-
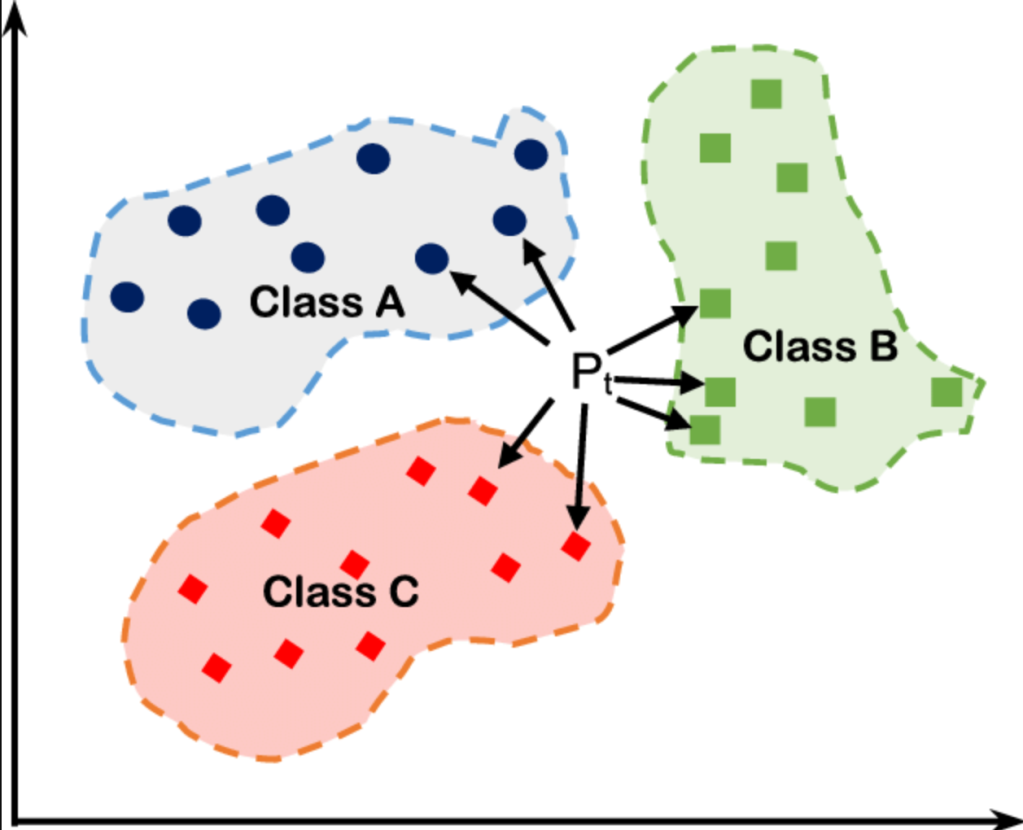
A Complete Guide to the K-NN Algorithm – K-Nearest Neighbours
K-Nearest Neighbors (KNN) is a supervised learning algorithm used for classification and regression tasks, known for its simplicity and effectiveness in handling irregular decision boundaries. It relies on the number of nearest neighbors (K) to make predictions and calculates distances using metrics like Euclidean, Manhattan, and Minkowski. KNN’s advantages include…
-

Logistic Regression
Logistic Regression is explained in detail in the blog post, including theoretical foundations and Python implementation. The post covers data preparation, probability calculation, odds and log odds, regression coefficients, error analysis, and comparison with scikit-learn’s LogisticRegression. It showcases the ease and efficiency of using libraries for logistic regression.
-

Unraveling the Threads: Assumptions of Linear Regression
Linear regression, a common statistical method, requires certain assumptions for valid analysis including linearity, homoscedasticity, multivariate normality, independence, and lack of multicollinearity. Additionally, checking for outliers, which significantly impact results, is crucial. By addressing these assumptions and outlier concerns, the analysis will yield more accurate and meaningful conclusions from a…
